決策樹算法
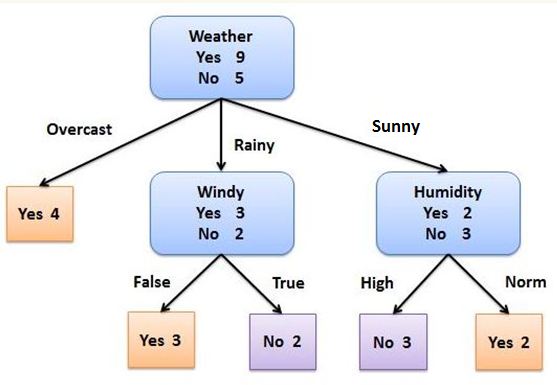
機器學習中,決策樹是一個預測模型;它代表的是對象屬性值與對象值之間的一種映射關系。樹中每個節點表示某個對象,每個分叉路徑則代表的某個可能的屬性值,而每個葉結點則對應具有上述屬性值的子對象。決策樹僅有單一輸出;若需要多個輸出,可以建立獨立的決策樹以處理不同輸出。
從數據產生決策樹的機器學習技術叫做決策樹學習, 通俗說就是決策樹。
關于決策樹,幾乎是數據挖掘分類算法中最先介紹到的。
決策樹,顧名思義就是用來做決定的樹,一個分支就是一個決策過程。
每個決策過程中涉及一個數據的屬性,而且只涉及一個。然后遞歸地,貪心地直到滿足決策條件(即可以得到明確的決策結果)。
決策樹算法:顧名思義,以二分類問題為例,即利用自變量構造一顆二叉樹,將目標變量區分出來,所有決策樹算法的關鍵點如下:
1.分裂屬性的選擇:選擇哪個自變量作為樹叉,也就是在n個自變量中,優先選擇哪個自變量進行分叉。而采用何種計算方式選擇樹叉,決定了決策樹算法的類型,即ID3、c4.5、CART三種決策樹算法選擇樹叉的方式是不一樣的。
2.樹剪枝:在構建樹叉時,由于數據中的噪聲和離群點,許多分支反映的是訓練數據中的異常,而樹剪枝則是處理這種過分擬合的數據問題,常用的剪枝方法為先剪枝和后剪枝。
決策樹是一種十分常用的分類方法。他是一種監管學習,所謂監管學習說白了很簡單,就是給定一堆樣本,每個樣本都有一組屬性和一個類別,這些類別是事先確定的,那么通過學習得到一個分類器,這個分類器能夠對新出現的對象給出正確的分類。這樣的機器學習就被稱之為監督學習。
構建一棵決策樹,關鍵問題就在于,如何選擇一個合適的分裂屬性來進行一次分裂,以及如何制定合適的分裂謂詞來產生相應的分支。各種決策樹算法的主要區別也正在于此。
利用決策樹算法構建一個初始的樹之后,為了有效地分類,還要對其進行剪枝。這是因為,由于數據表示不當、有噪音等原因,會造成生成的決策樹過大或過度擬合。因此為了簡化決策樹,尋找一顆最優的決策樹,剪枝是一個必不可少的過程。
決策樹學習也是數據挖掘中一個普通的方法。在管理學中,每個決策樹都表述了一種樹型結構,它由它的分支來對該類型的對象依靠屬性進行分類。每個決策樹可以依靠對源數據庫的分割進行數據測試。這個過程可以遞歸式的對樹進行修剪。當不能再進行分割或一個單獨的類可以被應用于某一分支時,遞歸過程就完成了。另外,隨機森林分類器將許多決策樹結合起來以提升分類的正確率。
行業分析發現,決策樹越小,就越容易理解,其存儲與傳輸的代價也就越小,但決策樹過小會導致錯誤率較大。反之,決策樹越復雜,節點越多,每個節點包含的訓練樣本個數越少,則支持每個節點樣本數量也越少,可能導致決策樹在測試集上的分類錯誤率越大。因此,剪枝的基本原則就是,在保證一定的決策精度的前提下,使樹的葉子節點最少,葉子節點的深度最小。要在樹的大小和正確率之間尋找平衡點。
在生成一棵最優的決策樹之后,就可以根據這棵決策樹來生成一系列規則。這些規則采用“If...,Then...”的形式。從根節點到葉子節點的每一條路徑,都可以生成一條規則。這條路徑上的分裂屬性和分裂謂詞形成規則的前件(If部分),葉子節點的類標號形成規則的后件(Then部分)。
相對于其他數據挖掘算法,決策樹在以下幾個方面擁有優勢:
決策樹易于理解和實現,人們在通過解釋后都有能力去理解決策樹所表達的意義。
對于決策樹,數據的準備往往是簡單或者是不必要的,其他的技術往往要求先把數據一般化,比如去掉多余的或者空白的屬性;
能夠同時處理數據型和常規型屬性;
是一個白盒模型如果給定一個觀察的模型,那么根據所產生的決策樹很容易推出相應的邏輯表達式;
易于通過靜態測試來對模型進行評測。 表示有可能測量該模型的可信度;
在相對短的時間內能夠對大型數據源做出可行且效果良好的結果。
知名風險投資公司
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||

創業聯合網是創業者和投資人的交流平臺。平臺擁有5000+名投資人入駐。幫助創業企業對接投資人和投資機構,同時也是創業企業的媒體宣傳和交流合作平臺。
熱門標簽(qian)
精華文章

